

“We don’t have time to adapt,” explains Prof Ben Herbst, data scientist at Praelexis, in a recent panel discussion about AI (artificial intelligence) and the world of work at Stellenbosch University. The discussion was moderated by Prof Deresh Ramjugernath and the panellists were tasked to explain how their different sectors engaged with AI. Stellenbosch University wants to position itself at the forefront of technological developments and this panel discussion aimed to help the university understand how they could connect the world of learning with the industrial world. Ben divided his discussion into two parts: (1) practical thoughts on AI (and ethics) and (2) ChatGPT.
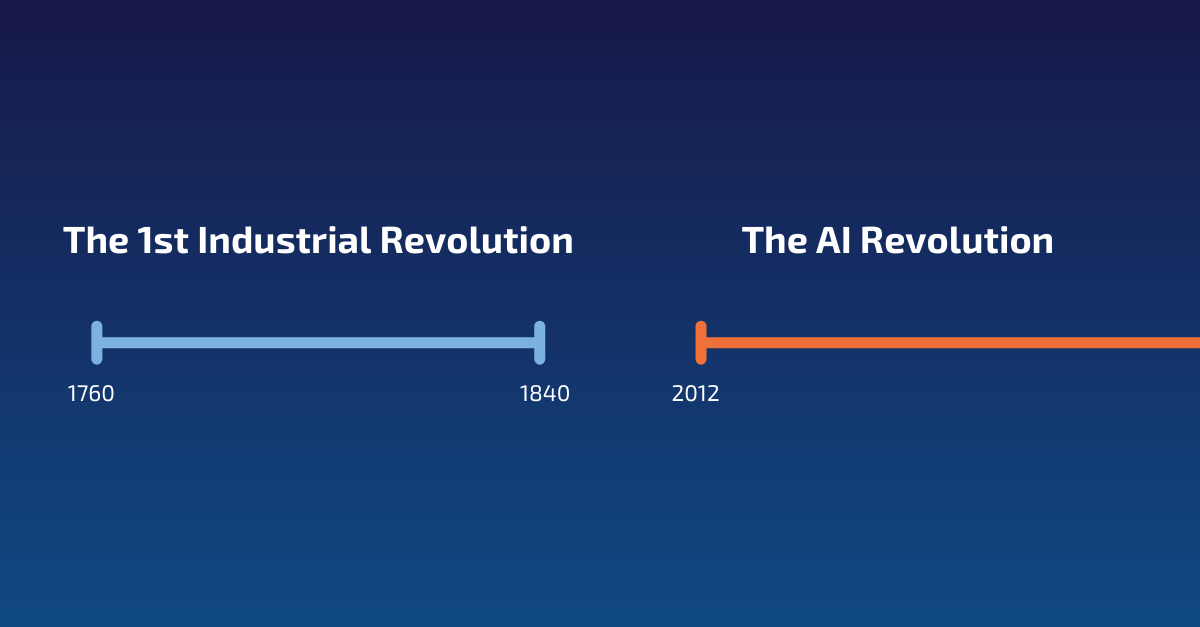
The AI Revolution
AI relieves us of mental labour. This is in contrast with the first industrial revolution (1760 - 1840) that relieved humans from manual labour. The advances in machine “intelligence” are seductive — tempting us to think less and rely more and more on machines to do our “thinking” for us. Less obvious, perhaps, is the timescale. The first industrial revolution took about 80 years, more than a full generation at that time. This allowed time to adjust. The AI revolution started only around 2012, leaving us no time to adjust and no time to prepare for the changes that are upon us.
Practical ethical guidelines for data scientists
As a data scientist, Ben shared three personal guidelines when it comes to actively working in the field of data science:
- Take full responsibility for the project
- Understand the problem
- Understand the data and keep control
.png?width=480&height=251&name=Blog%20Ben%20(1).png)
1. Taking full responsibility for the AI product
The data scientists who built the model are the only people who know the inner workings of the model, including its shortcomings. Even if companies implement a rigorous review process consisting of experts in the specific domain, it is hard, if not impossible, to get a detailed view of the implementation. In short, it is easy to miss something important. The data scientist as developer of the model, cannot and must not transfer its responsibility to a committee. This is where the buck stops.
What does it mean to take full responsibility for the AI product? According to Ben, you take responsibility by “thinking”. As previously mentioned, AI relieves us of mental labour. General software libraries are available and even someone with little or no expert knowledge can build rather sophisticated systems without any detailed understanding of what they are doing. This can easily lead to a disaster and the responsible data scientist will, for example, think carefully about aspects such as the origin and nature of the data, or the details of the algorithm that is used.

2. Understand the problem
In contrast to the “thinking” data scientist, generative AI, such as ChatGPT, is unable to think and understand. In the future, generative AI might empower data scientists to the extent that most if not all of the processes, including coding, are automated. The emphasis might therefore shift towards the data scientist with the domain knowledge — one that thoroughly understands the problem domain in all its complexity, the challenges and subtleties. Data scientists might find themselves spending most of their time explaining the problem to the generative AI system that will then convert it into a software solution. In short, the domain specialist, the engineer, the biologist, the social scientist, you name it, might become central to the future human-AI interactions.
 3. Understand the data
3. Understand the data
One of the ethical considerations when developing an AI model is the bias that it might reinforce. Two types of biases should be considered: (1) data bias and (2) societal bias. Data bias often reflects societal bias - there used to be more male than female engineers, for example. In some societies it is (hopefully) in the process of being erased. In many situations there is a severe lack of data in which case, data bias is inevitable. This includes any bias that does not reflect the reality of the situation. Expert human intervention is called for to remove bias derived from data, but that runs the risk of introducing the data scientist’s own bias. When that happens the model is no longer only data-informed.

ChatGPT within the world of learning
Students have to understand that what they have access to is a powerful weapon. It is easy to sacrifice all the good that has come from the developments in AI by misusing it. One of the questions that Ben raised was “Should we give credit to something that could have been generated by ChatGPT, even if it wasn’t?” Should we give credit to a human with all its cognitive abilities, if it is on the same par as that produced by a machine with no cognitive abilities?
This also raises something more existential. It was long thought that one of the ways in which humans are differentiated from other mammals is their mastery of language in which abstract thought can be communicated in aesthetic meaningful ways. Now that machines, apparently, have also acquired language skills, where do humans differ from other mammals and machines? And how can we make use of our uniquely human abilities to confront powerful “thinking” machines.
Prof Ramjugernath links to this and points towards two important considerations for the education sector:
1. Students need to be taught to “think” and value mental labour.
2. Students have to be able to understand the problem and adequately explain it.
The above-mentioned considerations should guide educators in their curriculum development and the way they approach learning.
In conclusion…
Ben highlighted how important it is for the education sector to adapt to the ongoing AI revolution. He stressed the need for data scientists to take responsibility for what they develop, understand the problem, be able to communicate it and critically consider the impact of potential bias in the data on individuals and society. As universities prepare themselves to be at the forefront of technological developments, they should consider the role of ChatGPT and be aware of the temptation to “think less” and produce more among students and educators alike.
The panel emphasized the importance of preparing for the evolving landscape of work and learning in the AI era.
Praelexis is a leader in the use of Responsible AI. If you are interested in speaking to our Responsible AI practitioners, please do not hesitate to reach out.
Recommended Sources:
Abu-Mostafa, Y. (2023). Artificial Intelligence: The Good, the Bad and the Ugly. caltech. Available at: https://www.youtube.com/watch?v=-a61zsRRONc (14 February 2024).
Berendt, B. (2022). The AI Act Proposal: Towards the next transparency fallacy? Why AI regulation should be based on principles based on how algorithmic discrimination works. To appear in BMJV & Rostalski, F. (Eds.), Künstliche Intelligenz - Wie gelingt eine vertrauenswürdige Verwendung in Deutschland und Europa? Tübingen, Germany: Mohr Siebeck.
Strümke, I. (2024). 2024 Election Superyear: What role will AI play? Power in Play. Available at: https://open.spotify.com/episode/4UqVIeLp8E6UaCT2Vbu6TU?si=9x0fZRx2TO2HwZxSIAHxOA&utm_content=175737836&utm_medium=social&utm_source=linkedin&hss_channel=lcp-5314071&nd=1&dlsi=b00c2e8eec274c5e (14 February 2024).
Lopez, P. (2021). Bias does not equal bias: a socio-technical typology of bias in data-based algorithmic systems. Internet Policy Review, 10(4). https://doi.org/10.14763/2021.4.1598
Internal peer review: Ben Herbst and Johan van der Merwe
Illustrations: Generated by AI
Image layout: Aletta Simpson
Stay to date on our blog posts, subscribe to our newsletter:
![]()


